I recently became curious about what information flow looks like in a p2p distributed system.
As peers produce new data, they send messages to the other peers. It is impossible to know the exact order in which messages were produced, so the best we can do is to partially order them. I wanted to use this partial ordering property to create a graph visualization from an array of messages that looks like this:
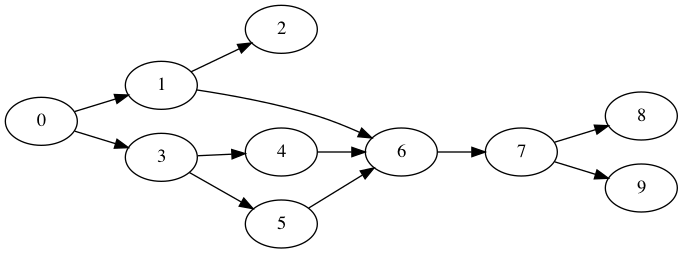
Notice how this graph uses the minimum number of edges to represent relationships between nodes. The messages have these relationships, 0 -> 1, 1 -> 2, and 0 -> 2 (transitively), but we don’t draw 0 -> 2 because it is redundant.
Creating an algorithm that can produce a graph like this is not hard. The challenge is making the algorithm fast. My first solution was very slow and took over 60 seconds to build a graph for 400 nodes. After finding a paper from 1972, and optimizing my code with Accelerate (a vector processing framework), I managed to speed up my solution to complete in < 1 second.
Attempt 1: Algorithm Built From Scratch
From my undergrad data structures class, I remembered that I could do a topological sort on partially ordered elements. This sort guarantees that for any 2 elements A[i], and A[j] it is not possible for A[i] > A[j] if i < j. In other words, if an element is at index 5, all elements less than it must be located at indices 0 through 4.
Once the elements are sorted, we iterate over each element and try to find its minimal set of neighbors. To find an elements neighbors, we create a prefix array from elements 0 … i-1 and iterate over this list backwards. For each neighbor candidate, we add it to A[i]’s neighbors only if it is not already reachable via graph traversal by another one of its neighbors.
In Swift-like psuedo code, the algorithm looks like this:
protocol PartialOrder {
func lessThan(other: Node) -> Bool
}
struct Node: PartialOrder, Comparable {
...
}
func partialOrderGraph(nodes: [Node]) -> [Node: [Node]] {
var graph: [Node: [Node]] = []
let sortedNodes = nodes.sorted() // O(n log n)
for (i, fromNode) in sortedNodes.enumerated() { // O(n)
let prefixNodes = sortedNodes.upTo(i).reversed()
for toNode in prefixNodes { // O(n)
if !reachable(graph, fromNode, toNode) { O(n + e)
graph[fromNode].append(toNode)
}
}
}
return graph
}This algorithm has a run time of O(n n (n + e)). Roughly speaking it is O(n^3). On my computer it takes 60 seconds to complete for 400 nodes.
This felt extremely slow, and I wondered if we could do better than this.
Attempt 2: Naive Transitive Reduction
Maybe there were existing algorithms that could help. I have seen graphs similar to the one I was trying to build, so I felt that there might be an existing algorithm I could use.
I searched for “how to graph partially ordered set algorithm”, and came across this Stack Overflow post which was exactly what I was looking for. According to the post, the type of graph I am trying to make is a Hasse diagram. One answer pointed out that the algorithm used to construct a Hasse diagram is called a transitive reduction . I learned from Wikipedia that the transitive reduction of a graph produces a graph that maintains transitive relationships with as few nodes as possible. If A->B, B->C, and A->C, the transitive reduction would remove A->C.
This sounded like exactly what I was looking for.
I looked around for some sample code that implemented this algorithm, but didn’t find anything so I went to the original paper published in 1972. Sidenote: The first author, Alfred Aho is also the author of AWK, the “dragon” book for compilers, and the Aho-Corasick algorithm!
The algorithm is fairly straight-forward. Here’s some psuedo code that implements the algorithm as written:
func transitiveReduction(nodes: [Node]) -> [Node: [Node]] {
// In total this is O(n^3)
let transClosureMat = transitiveClosureMatrix(nodes: nodes)
let multMat = multiply(m1: transClosureMat, m2: transClosureMat)
let result = subtract(m1: transClosureMat, m2: multMat)
let graph = adjacencyList(nodes: nodes, matrix: result)
return graph
}
func transitiveClosureMatrix(nodes: [Node]) -> [[Bool]] {
// O(n^2)
// if there are N nodes, returns an N x N matrix
// where each value (i, j) is `true` if there exists
// a path from i -> j
}
func multiply(m1: [[Bool]], m2: [[Bool]]) -> [[Bool]] {
// O(n^3)
// Works the same way as traditional matrix multiplication,
// except you replace `*` with `&&`, and `+` with `||`
}
func subtract(m1: [[Bool]], m2: [[Bool]]) -> [[Bool]] {
// O(n^2)
// Subtraction of 2 `Bool`s is defined as follows:
// true - false = true
// true - true = false
// false - true = false
// false - false = false
}
func adjacencyList(nodes: [Node], matrix: [[Bool]]) -> [Node: [Node]] {
// O(n^2)
// converts an adjacency matrix to an adjacency list.
// Indices in the matrix correspond to the indices in `nodes`.
// For each (i, j) where matrix[i][j] == true,
// we add a connection nodes[i] -> nodes[j] in the adjacency list
}Unfortunately, this algorithm was actually slower than my initial solution! On average it took about 5 extra seconds.
Since the matrix multiplication has a runtime complexity of O(n^3), I felt that is where the bulk of the time was being spent. If I could find a way to speed up the matrix multiplication, I might be able to speed up the overall algorithm significantly.
I considered trying to read up on research on matrix multiplication math. I wondered if there were optimizations for Boolean matrices, or for the case where you try to square a matrix. I was just about to start researching those topics, when I was struck with an idea: What if the matrix multiplication was slow because I was just using a poor implementation?
I remembered that there is a framework available on macOS called Accelerate that provides fast implementations for vector math. In that past, I have used it to compute the FFT of audio/image data. Maybe it had functions for matrix multiplication too.
Approach 3: “Accelerated” Transitive Reduction
I searched through the API of Accelerate and found a matrix multiplication function: vDSP_mmul. It only works for Floats, but I thought I could make it work.
Instead of refactoring my code to use Float matrices, I decided to try replacing the implementation of multiply(m1:, m2:) with vDSP_mmul by converting my Bool matrices to/from Float matrices as needed. If using vDSP_mmul didn’t significantly speed up the matrix multiplication, there was no point optimizing other parts of the code.
Here is the rough approach I took:
- Convert each
Boolmatrix into a linearFloatarray. True = 1.0, and False = 0.0 - Use
Accelerateto do matrix multiplication on theseFloatarrays. - Convert the output
Floatarray back into aBoolmatrix
Here is some pseudo code:
func multiplyFast(m1: [[Bool]], m2: [[Bool]]) -> [[Bool]] {
// O(n^3)
let floatLHS = floatArray(mat: m1)
let floatRHS = floatArray(mat: m2)
var floatResult: [Float] = Array(repeating: 0.0, count: m1.count * m1.count)
let n: UInt = UInt(m1.count)
vDSP_mmul(
floatLHS, 1,
floatRHS, 1,
&floatResult, 1,
n, n, n
)
return boolMatrix(arr: floatResult, n: m1.count)
}
func floatArray(mat: [[Bool]]) -> [Float] {
...
}
func boolMatrix(arr: [Float], n: Int) -> [[Bool]] {
...
}
This time, the algorithm ran much faster. For 400 elements, it took < 1 second to complete!
I was so surprised by this result, that I assumed I must have a bug somewhere. I spent a bunch of time validating that there were no bugs, and that the result of this approach were equivalent to the result of approach 1. Fortunately there were no bugs I could find. Accelerate is just insanely fast!
Conclusion
I started out on this project just trying to draw some cool graphs in Graphviz. I ended up learning some graph theory, and using a vector processing framework called Accelerate to make my algorithm fast.
The graphs I was trying to make are called Hasse Diagrams and creating them requires computing the transitive reduction over a list of partially ordered elements. The standard algorithm for the transitive reduction has a runtime complexity of O(n^3). This produces a very slow run time with a naive implementation, but can be sped up significantly using a vector processing framework like Accelerate.
I hope you enjoyed this post. Please let me know if you have any comments, questions, or criticisms. I love it when people contact me, so please don’t be shy. The best way to reach me is via email, or via twitter.